Shaon Bhattacharjee
Shaon Bhattacharjee
ইন্টারনেট ব্যবহার করেন কিন্তু গুগলে গুগল করেননি, এমন মানুষ খুঁজে পাওয়া দুষ্কর! যেকোনো প্রয়োজনে গুগলে গিয়ে সার্চ করা আমাদের ইন্টারনেট জীবনের অবিচ্ছেদ্য অঙ্গ। গুগলে গিয়ে আমরা এতোই গুগল করি যে গুগল ছাড়াও যে আরও সার্চ ইঞ্জিন আছে- তা হয়ত সবসময় আমাদের মাথায় থাকে না! bing, yahoo, duckduckgo- এর মতো নানান রকম ও বাহারের সার্চ ইঞ্জিনও কিন্তু রয়েছে এবং এদের সংখ্যাটাও নেহায়েত কম নয়। সবথেকে মজার ব্যাপার হলো, এগুলোর প্রায় প্রতিটিরই কিছু না কিছু ভিন্নতা রয়েছে। তবে জনপ্রিয়তার দিক থেকে এখন গুগলই সবার উপরে।
সার্চ ইঞ্জিন কীভাবে কাজ করে সেটা জানার আগে যে জিনিসটা জানা দরকার তা হলো- সার্চ ইঞ্জিন কী? যদিও আমরা প্রত্যেকেই সার্চ ইঞ্জিন ব্যবহার করে অভ্যস্ত, তবুও ধারণাটা একটু পরিষ্কার করে নেওয়া প্রয়োজন। সহজ করে বলতে গেলে, সার্চ ইঞ্জিন হল এক ধরনের সফটওয়্যার সিস্টেম যা World Wide Web (WWW)-এ বিদ্যমান অন্যান্য সাইট থেকে তথ্য খুঁজে নিতে আমাদের সাহায্য করে।
আপনার কোনো বিষয়ে তথ্য দরকার? অমনি গুগল ওপেন করে সার্চ করলেন, আর মুহূর্তের মাঝেই লক্ষ লক্ষ ফলাফল এসে হাজির! আবার মাঝেমধ্যে এমনও হয়, আপনি একটি ভুল ওয়ার্ড লিখে সার্চ করলেন, কিন্তু গুগল ঠিকই ওটাকে শুদ্ধ করে রেজাল্ট দেখিয়ে দিল! অথবা আপনি এমন কিছু একটা সার্চ করতে যাচ্ছেন যা সম্পর্কে আপনার ধারণা নগণ্য। আন্দাজের উপর কিছু একটা লিখে সার্চ দিলেন। কিন্তু কিছুক্ষণের মধ্যেই দেখলেন গুগল আবারো আপনার মনের কথা বুঝে নিয়ে তথ্য আপনার সামনে এনে হাজির করেছে! আর এসব ফলাফল বের করে দিতে কিংবা আপনার মনের কথা বুঝে নিতে গুগল সময় নিলো এক সেকেন্ডের কম সময়! পুরো ওয়েবের বিলিয়ন বিলিয়ন সাইট ঘেঁটে ১ সেকেন্ডের কম সময় নিয়ে আপনার সার্চ করা তথ্য বের করে দেওয়া নিশ্চয়ই চাট্টিখানি কথা নয়! মনে প্রশ্ন নিশ্চয়ই উঁকি দিচ্ছে, এটা কীভাবে সম্ভব? কিন্তু আমরা বলবো, এটা কি আদৌ সম্ভব? পাঠকরা হয়তো মনে মনে ভাবছেন, সম্ভব না হলে রেজাল্ট দেখায় কী করে! হ্যাঁ, গুগল রেজাল্ট দেখাচ্ছে ঠিকই। কিন্তু হয়তো আপনি যেভাবে চিন্তা করছেন ঠিক সেভাবে নয়।

Source: linkterkep.info
আগেই বলেছি, ওয়েবে গুগলই একমাত্র সার্চ ইঞ্জিন নয়। প্রত্যেক সার্চ ইঞ্জিন আলাদা আলাদাভাবে তাদের গ্রাহকদেরকে সেবা দিয়ে থাকে। তাই একটি সার্চ ইঞ্জিনের কাজের ধারা আরেকটির সাথে কখনোই সম্পূর্ণ মিলবে না। তবে প্রতিটি সার্চ ইঞ্জিনই এই ধাপগুলো অনুসরণ করে:
- তারা ওয়েবে সার্চ করে গুরুত্বপূর্ণ শব্দের উপর ভিত্তি করে কয়েকটি ভাগ করে।
- যে শব্দগুলো খুঁজে বের করা হলো, সেগুলোকে নিয়ে ইনডেক্স তৈরি করে।
- ব্যবহারকারীদের সার্চ করা ওয়ার্ডগুলোকে তারা তাদের ইনডেক্সের সাথে মিলিয়ে দেখে।
পুরনো সার্চ ইঞ্জিনগুলো বড়জোর কয়েকশ’ পেজের ইনডেক্স তৈরি করতো। প্রতিদিন হয়ত এতে কয়েক হাজার সার্চ করা হতো। কিন্তু এখনকার একেকটি সার্চ ইঞ্জিন কয়েক মিলিয়ন পেজকে ইনডেক্স করে। আর প্রতিদিনই আরও কয়েক মিলিয়ন সার্চ রেজাল্ট দেখাতে হয় এদেরকে। ব্যাপারগুলো একটু জটিল মনে হচ্ছে তো? না, খুব জটিল কিছু নয়। এখন এই প্রধান ধাপগুলো একে একে ব্যখ্যা করবো।
ওয়েব ক্রলিং (Web Crawling)
‘Web’ মানে ‘জাল’। অন্যদিকে ‘Crawl’- শব্দের বাংলা ‘হামাগুড়ি দেয়া’। তার মানে ‘Web Crawling’ এর সোজা বাংলা দাঁড়াচ্ছে জালের উপর দিয়ে হামাগুড়ি দেয়া। কিন্তু এই হামাগুড়ি দিচ্ছে কে? উত্তর হল ‘স্পাইডার’! অদ্ভুত লাগছে? হ্যাঁ, সেটাই স্বাভাবিক।
যখন আপনি গুগলে সার্চ করছেন, তখন প্রতিবারই গুগল আপনাকে ফলাফল দেখাচ্ছে। কিন্তু ফলাফল আপনাকে দেখানোর আগে অবশ্যই গুগলকে নিজে ফলাফল বের করতে হচ্ছে। এই কাজটি করার জন্য সার্চ ইঞ্জিনগুলো বিশেষায়িত সফটওয়্যার রোবট তৈরি করে। এদেরকে বলা হয় ‘স্পাইডার’। পুরো ওয়েবে ঘুরে বেড়ানো আর সবকিছু লিপিবদ্ধ করাটাই এর কাজ। ঠিক যেমন মাকড়সা তার জালের উপর দিয়ে ঘুরে বেড়ায়, তেমনি। আর এই প্রক্রিয়াকেই বলা হয় ওয়েব ক্রলিং।

Source: medium.com
এখন প্রশ্ন হলো, স্পাইডার কীভাবে এই বিশালাকার ওয়েবে ভ্রমণ শুরু করে? সাধারণত এদের শুরু হয় জনপ্রিয় কিছু ওয়েবসাইট ভ্রমণের মধ্য দিয়ে। প্রথমে স্পাইডার এসব জনপ্রিয় পেজ থেকে শব্দগুলো সংগ্রহ করে। একইসাথে এটাও সংরক্ষণ করে যে শব্দগুলো কোথা থেকে পাচ্ছে। তারপর ঐ সাইটে থাকা অন্যান্য পেজের লিংক অনুসরণ করে। তারপর ঐসব পেজে গিয়ে ঐখানে থাকা অন্যান্য লিংকও অনুসরণ করে। আর এভাবেই চলতে থাকে স্পাইডারের ভ্রমণ। স্পাইডার একটা নির্দিষ্ট সময় পরপর সাইটগুলোতে ঢুকে দেখে কোনো পরিবর্তন করা হয়েছে কিনা। যেমন: এই যে আর্টিকেল প্রকাশিত হয়েছে, তা কিন্তু কেউ গুগলের স্পাইডারকে জানায়নি। কিন্তু এখন যদি আপনি এই লেখার শিরোনাম দিয়ে গুগলে সার্চ করেন, তাহলে দেখবেন এটাই চলে এসেছে ফলাফলে। স্পাইডার এই আর্টিকেলের ব্যপারে না জানলেও Roar বাংলা– এর ব্যাপারে কিন্তু জানে। তাই সে স্বাভাবিকভাবেই Roar বাংলাতে ঢুকে প্রতিটি লিংক অনুসরণ করে তার তথ্য ভান্ডার সমৃদ্ধ করে নিয়েছে। আর সেখানে এই লেখাকেও ক্রল (Crawl) করে নিয়েছে। স্পাইডার যখন একটি পেজে যায় তখন ঐ পেজে থাকা প্রতিটি শব্দ নোট করে, একই শব্দ কতবার ব্যবহার করা হয়েছে তা-ও নোট করে। যেমন, গুগল স্পাইডারকে এমনভাবে তৈরি করা হয়েছে যাতে সেটি ‘a’, ‘an’, ‘the’- এই ওয়ার্ডগুলো ছাড়া আর্টিকেলের অন্যান্য শব্দসমূহের ইনডেক্স তৈরি করতে পারে। কিন্তু সকল সার্চ ইঞ্জিন যে একই কৌশল অনুসরণ করবে, এমন কোনো কথা নেই।

Source: seon.co.id
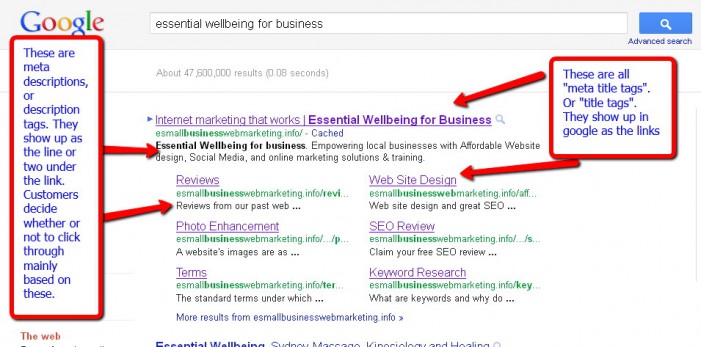
মেটা ট্যাগস (Meta Tags)
সহজ ভাষায় মেটা ট্যাগ হল বিশেষ ধরনের HTML ট্যাগ যা সংক্ষিপ্তরূপে একটি পেজের বিষয়বস্তু সম্পর্কে ধারণা দেয়। আমরা সবাই বিভিন্ন ব্লগে ট্যাগ দেখেছি। মেটা ট্যাগের কাজও এর মতোই, বিষয়বস্তু সম্পর্কে সংক্ষিপ্ত ধারণা দেওয়া। ব্লগের ট্যাগ আপনাকে-আমাকে ধারণা দেয়। আর অন্যদিকে মেটা ট্যাগ এই ধারণাটি দেয় সার্চ ইঞ্জিনকে। কোনো লেখায় একটি শব্দের দুটি বা তিনটি অর্থও থাকতে পারে! সে ক্ষেত্রে মেটা ট্যাগ খুবই কার্যকরী ভূমিকা পালন করে। তবে মেটা ট্যাগের ব্যবহারে প্রায় সময়ই যে সমস্যা হয় তা হল- পেজের মালিকরা অনেক সময়ই এমন মেটা ট্যাগ বসিয়ে দেন যেগুলোর মূল লেখার সাথে সামঞ্জস্য থাকে না। এই সমস্যা দূর করতে সার্চ ইঞ্জিনের স্পাইডাররা মেটা ট্যাগকে পেজের অভ্যন্তরীণ শব্দগুলোর সাথে মিলিয়ে দেখে।
ইনডেক্স তৈরি করা
যখন স্পাইডার ওয়েব থেকে তথ্য সংগ্রহ করা শেষ করে, তখন তথ্যগুলোকে সংরক্ষণ করা হয়। এখানে একটা বিষয় খেয়াল রাখবেন, ‘তথ্য সংগ্রহ শেষ করা’ মানে কিন্তু একেবারে বন্ধ করে দেওয়া নয়। স্পাইডার সবসমই ক্রলিং করতে থাকে। যার ফলে তথ্য আর ইনডেক্সের হারহামেশাই পরিবর্তন ঘটে। ‘তথ্য সংগ্রহ শেষ করা’ বলতে একটি নির্দিষ্ট সময়ে সংগ্রহ করা তথ্যকে ধরে নিতে পারেন। যা-ই হোক, এই ধাপে সংগৃহীত তথ্যের ব্যবহার করে ইনডেক্স তৈরি হয়। ইনডেক্সে শব্দ ও তার URLগুলোর তালিকা থাকে। প্রতিটি সার্চ ইঞ্জিনের ইনডেক্স তৈরির কৌশল ভিন্ন। একটি পেজের কোন শব্দে কতটুকু গুরুত্বারোপ করা হবে, তা ঠিক করে দেয়া হয়। অর্থাৎ এটা সম্পূর্ণ সার্চ ইঞ্জিন কর্তৃপক্ষের উপর নির্ভর করে তারা কী ধরনের মাপকাঠি ব্যবহার করবেন।
Source: thedevline.com
আশা করি এতক্ষণে পাঠক বুঝে গেছেন, সার্চ ইঞ্জিন আসলে কীভাবে কাজ করে। লেখার প্রথম দিকে একটা প্রশ্ন করেছিলাম, মনে আছে? এখন তার উত্তর দিচ্ছি। আপনি যখন কিছু লিখে গুগলে সার্চ করছেন তখন কিন্তু আপনি পুরো ওয়েবে সার্চ করছেন না। আপনি সার্চ করছেন ঐ সার্চ ইঞ্জিনের তথা গুগলের ইনডেক্সে, যা কিনা আগে থেকেই তৈরি করা আছে। তৎক্ষণাৎ গুগলকে পুরো ওয়েবে খুঁজতে হচ্ছে না। এর ফলেই ১ সেকেন্ডের কম সময় নিয়েও গুগল আপনার কম্পিউটারের স্ক্রীনে তা তুলে ধরতে পারছে।
আরেকটি বিষয় হয়তো খেয়াল করে থাকবেন, প্রতিটা সার্চ ইঞ্জিনে একই শব্দ লিখে সার্চ দিলে কিন্তু একই ফলাফল আসে না। এর কারণ অনুমান করতে পারছেন? এর কারণ প্রতিটি সার্চ ইঞ্জিনের ইনডেক্সের ভিন্নতা। তবে এর সাথে আরেকটি ব্যাপারও আছে। সেটি হলো একেক সার্চ ইঞ্জিনের একেক ধরনের অ্যালগরিদমের ব্যবহার। সার্চ ইঞ্জিন যার মাধ্যমে আপনার সার্চ করা শব্দকে তার নিজের ইনডেক্সের সাথে মিলিয়ে দেখে, সেটা হলো অ্যালগরিদম। আর প্রধানত এই দুই কারণেই প্রতিটি সার্চ ইঞ্জিনে একই সার্চ করা সত্ত্বেও আপনি ভিন্ন ভিন্ন ফলাফল পান।
ইন্টারনেটের সবচেয়ে ভালো ব্যাপার হলো এখানে মিলিয়ন-মিলিয়ন পেজ আছে আমাদেরকে বিভিন্ন তথ্য দেওয়ার জন্য। আর সবচেয়ে বাজে ব্যাপার হলো, এখানে বিলিয়ন-বিলিয়ন পেজ আছে যেগুলোর খবর সাধারণত আপনি বা আমি কেউ-ই জানতে পারি না। আমরা সাধারণত ওয়েব বলতে যতটুকু আন্দাজ করি, ওয়েব আসলে তার থেকে আরও অনেক গুণ বড়! কিন্তু সে জায়গাগুলোতে গুগলের মতো প্রচলিত সার্চ ইঞ্জিন পৌঁছাতে পারে না। তাই পরবর্তী লেখায় হাজির হবো ওয়েবের সেই অংশ নিয়ে, যেখানে গুগলেরও ঢুকতে মানা!